CREATE TABLE [dbo].[FriendBookUpdates](
[Id] [uniqueidentifier] NOT NULL,
[PostedDate] [datetime] NOT NULL,
[Body] [nvarchar](256) NOT NULL,
[UserId] [uniqueidentifier] NOT NULL,
CONSTRAINT [PK_FriendBookUpdates] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
-- etc...Posts tagged with 'data modeling'
This is a repost that originally appeared on the Couchbase Blog: SQL to JSON Data Modeling with Hackolade.
SQL to JSON data modeling is something I touched on in the first part of my "Moving from SQL Server to Couchbase" series. Since that blog post, some new tooling has come to my attention from Hackolade, who have recently added first-class Couchbase support to their tool.
In this post, I’m going to review the very simple modeling exercise I did by hand, and show how IntegrIT’s Hackolade can help.
I’m using the same SQL schema that I used in the previous blog post series; you can find it on GitHub (in the SQLServerDataAccess/Scripts folder).
Review: SQL to JSON data modeling
First, let’s review, the main way to represent relations in a relational database is via a key/foreign key relationship between tables.
When looking at modeling in JSON, there are two main ways to represent relationships:
-
Referential - Concepts are given their own documents, but reference other document(s) using document keys.
-
Denormalization - Instead of splitting data between documents using keys, group the concepts into a single document.
I started with a relational model of shopping carts and social media users.
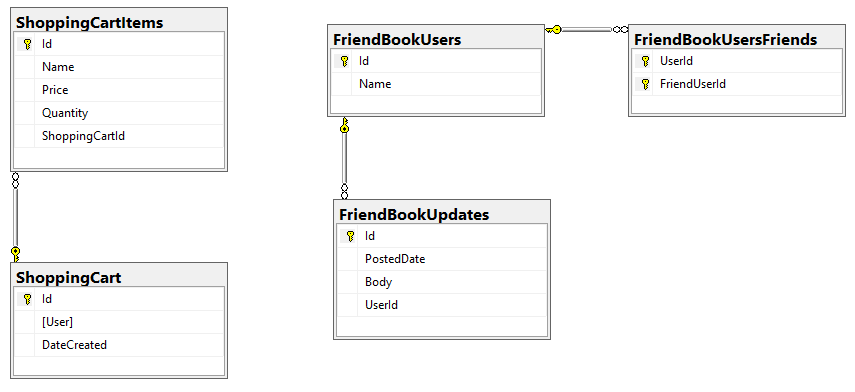
In my example, I said that a Shopping Cart - to - Shopping Cart Items relationship in a relational database would probably be better represented in JSON by a single Shopping Cart document (which contains Items). This is the "denormalization" path. Then, I suggested that a Social Media User - to - Social Media User Update relationship would be best represented in JSON with a referential relationship: updates live in their own documents, separate from the user.
This was an entirely manual process. For that simple example, it was not difficult. But with larger models, it would be helpful to have some tooling to assist in the SQL to JSON data modeling. It won’t be completely automatic: there’s still some art to it, but the tooling can do a lot of the work for us.
Starting with a SQL Server DDL
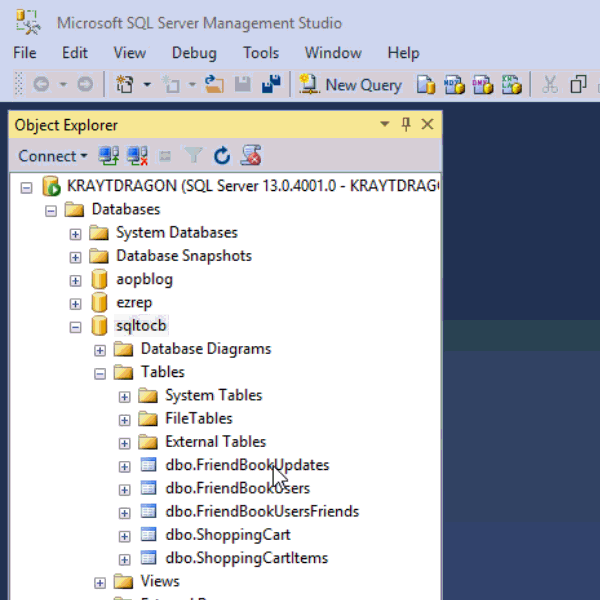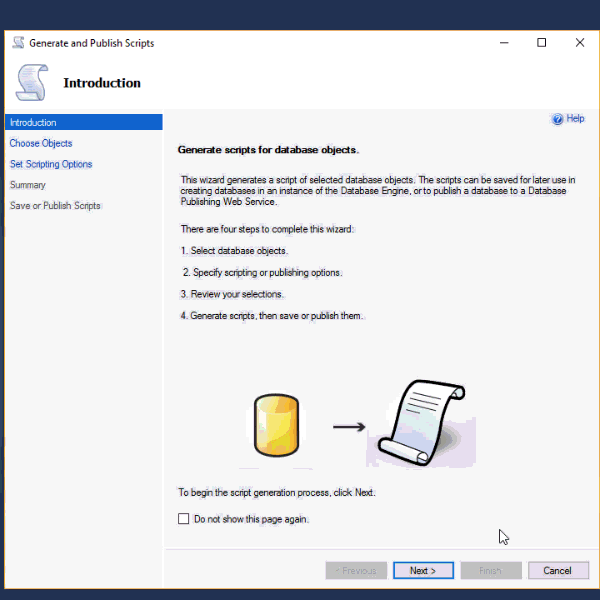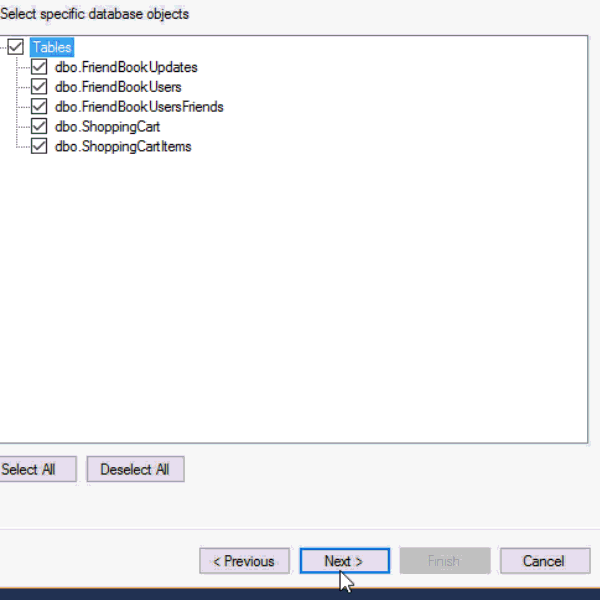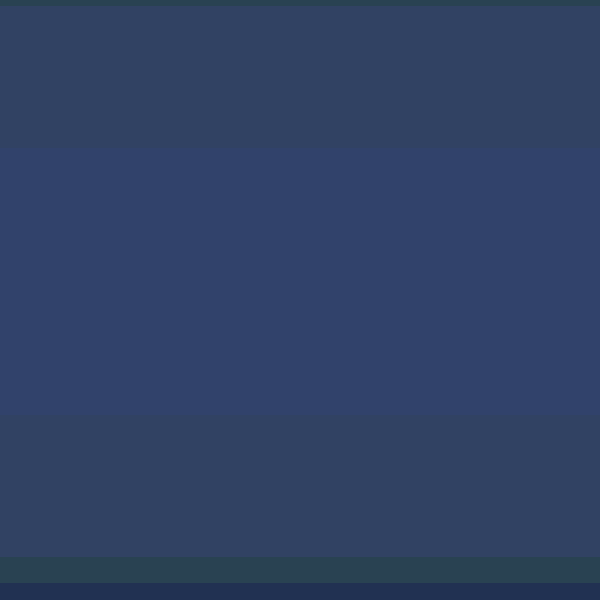
This next part assumes you’ve already run the SQL scripts to create the 5 tables: ShoppingCartItems, ShoppingCart, FriendBookUsers, FriendBookUpdates, and FriendBookUsersFriends. (Feel free to try this on your own databases, of course).
The first step is to create a DDL script of your schema. You can do this with SQL Server Management Studio.
First, right click on the database you want. Then, go to "Tasks" then "Generate Scripts". Next, you will see a wizard. You can pretty much just click "Next" on each step, but if you’ve never done this before you may want to read the instructions of each step so you understand what’s going on.
Finally, you will have a SQL file generated at the path you specified.
This will be a text file with a series of CREATE and ALTER statements in it (at least). Here’s a brief excerpt of what I created (you can find the full version on Github).
By the way, this should also work with SQL Azure databases.
Note: Hackolade works with other types of DDLs too, not just SQL Server, but also Oracle and MySQL.
Enter Hackolade
This next part assumes that you have downloaded and installed Hackolade. This feature is only available on the Professional edition of Hackolade, but there is a 30-day free trial available.
Once you have a DDL file created, you can open Hackolade.
In Hackolade, you will be creating/editing models that correspond to JSON models: Couchbase (of course) as well as DynamoDB and MongoDB. For this example, I’m going to create a new Couchbase model.
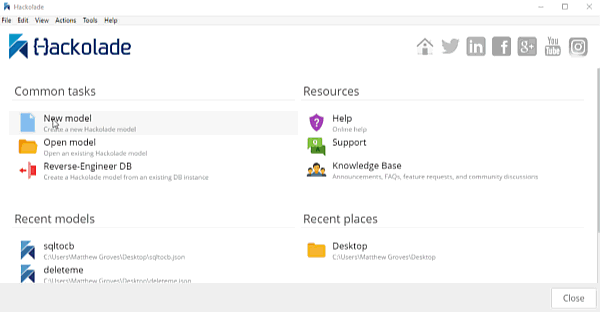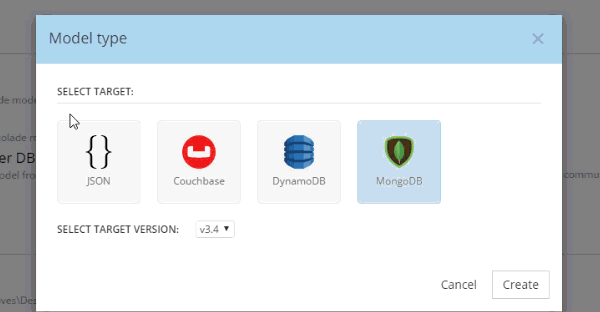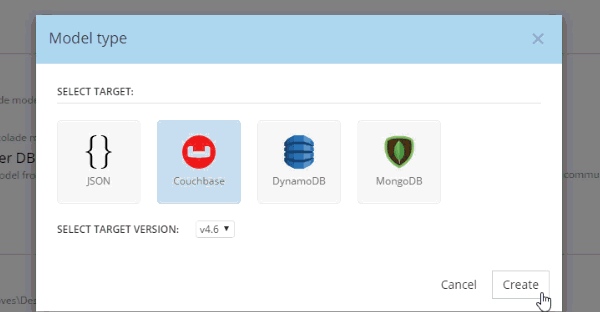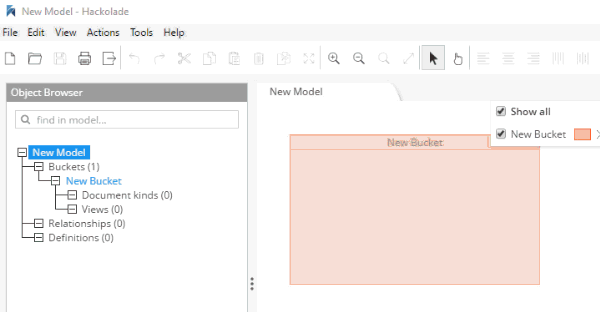
At this point, you have a brand new model that contains a "New Bucket". You can use Hackolade as a designing tool to visually represent the kinds of documents you are going to put in the bucket, the relationships to other documents, and so on.
We already have a relational model and a SQL Server DDL file, so let’s see what Hackolade can do with it.
Reverse engineer SQL to JSON data modeling
In Hackolade, go to Tools → Reverse Engineer → Data Definition Language file. You will be prompted to select a database type and a DDL file location. I’ll select "MS SQL Server" and the "script.sql" file from earlier. Finally, I’ll hit "Ok" to let Hackolade do its magic.

Hackolade will process the 5 tables into 5 different kinds of documents. So, what you end up with is very much like a literal translation.
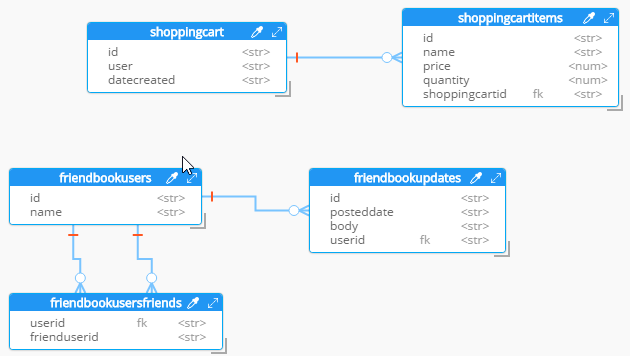
This diagram gives you a view of your model. But now you can think of it as a canvas to construct your ultimate JSON model. Hackolade gives you some tools to help.
Denormalization
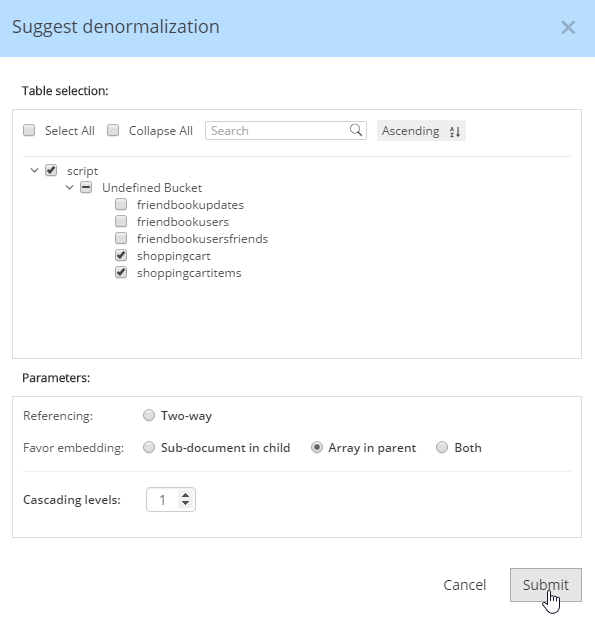
For instance, Hackolade can make suggestions about denormalization when doing SQL to JSON data modeling. Go to Tools→Suggest denormalization. You’ll see a list of document kinds in "Table selection". Try selecting "shoppingcart" and "shoppingcartitems". Then, in the "Parameters" section, choose "Array in parent".
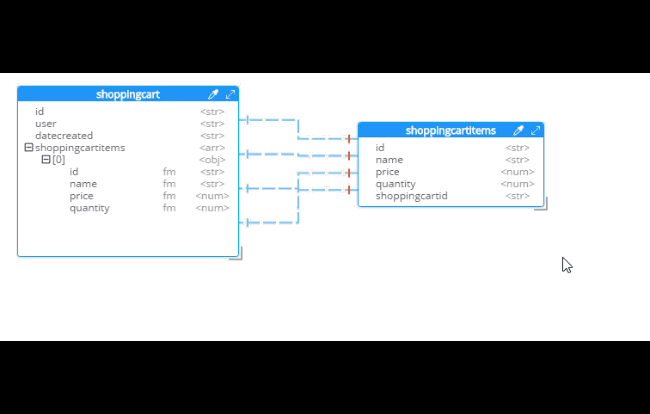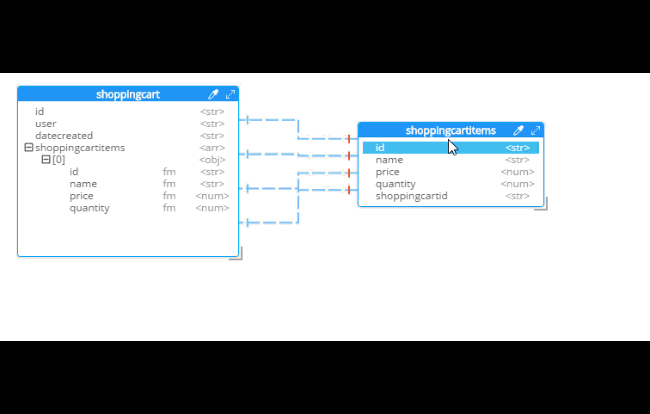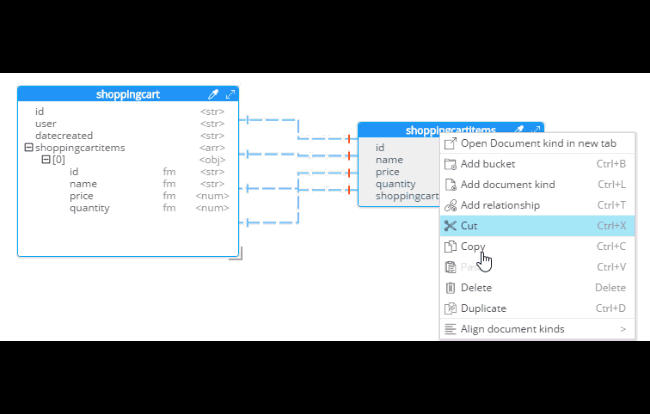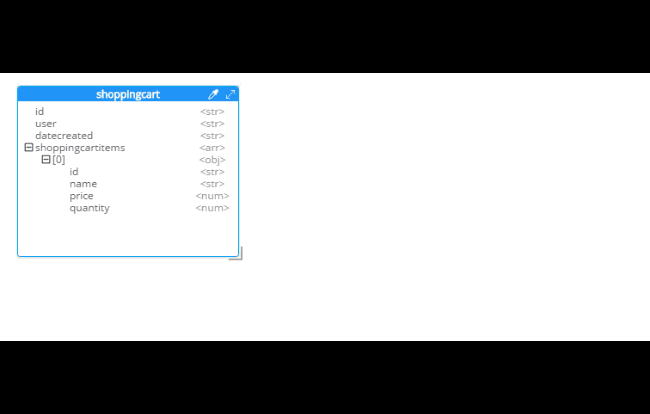
After you do this, you will see that the diagram looks different. Now, the items are embedded into an array in shoppingcart, and there are dashed lines going to shoppingcartitems. At this point, we can remove shoppingcartitems from the model (in some cases you may want to leave it, that’s why Hackolade doesn’t remove it automatically when doing SQL to JSON data modeling).
Notice that there are other options here too:
-
Embedding Array in parent - This is what was demonstrated above.
-
Embedding Sub-document in child - If you want to model the opposite way (e.g. store the shopping cart within the shopping cart item).
-
Embedding Both - Both array in parent and sub-document approach.
-
Two-way referencing - Represent a many-to-many relationship. In relational tables, this is typically done with a "junction table" or "mapping table"
Also note cascading. This is to prevent circular referencing where there can be a parent, child, grandchild, and so on. You select how far you want to cascade.
More cleanup
There are a couple of other things that I can do to clean up this model.
-
Add a 'type' field. In Couchbase, we might need to distinguish shoppingcart documents from other documents. One way to do this is to add a "discriminator" field, usually called 'type' (but you can call it whatever you like). I can give it a "default" value in Hackolade of "shoppingcart".
-
Remove the 'id' field from the embedded array. The SQL table needed this field for a foreign key relationship. Since it’s all embedded into a single document, we no longer need this field.
-
Change the array name to 'items'. Again, since a shopping cart is now consolidated into a single document, we don’t need to call it 'shoppingcartitems'. Just 'items' will do fine.

Output
A model like this can be a living document that your team works on. Hackolade models are themselves stored as JSON documents. You can share with team members, check them into source control, and so on.
You can also use Hackolade to generate static documentation about the model. This documentation can then be used to guide the development and architecture of your application.
Go to File → Generate Documentation → HTML/PDF. You can choose what components to include in your documentation.
Summary
Hackolade is a NoSQL modeling tool created by the IntegrIT company. It’s useful not only in building models from scratch, but also in reverse engineering for SQL to JSON data modeling. There are many other features about Hackolade that I didn’t cover in this post. I encourage you to download a free trial of Hackolade today. You can also find Hackolade on Twitter @hackolade.
If you have questions about Couchbase Server, please ask away in the Couchbase Forums. Also check out the Couchbase Developer Portal for more information on Couchbase for developers. Always feel free to contact me on Twitter @mgroves.
